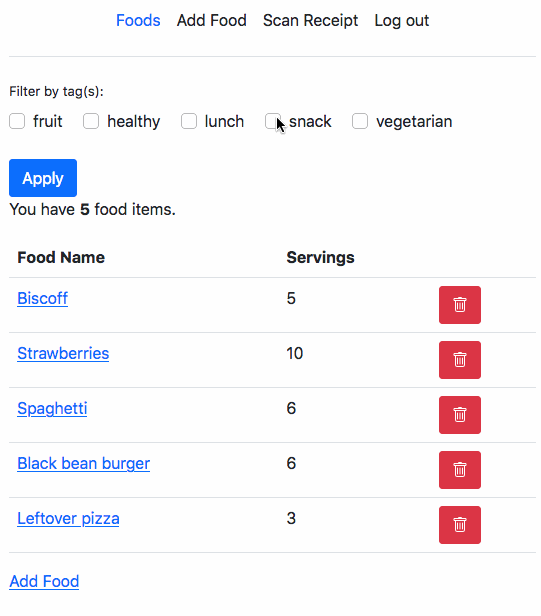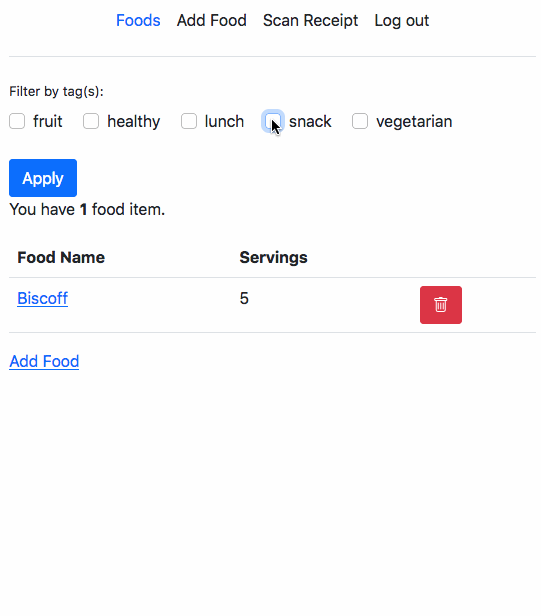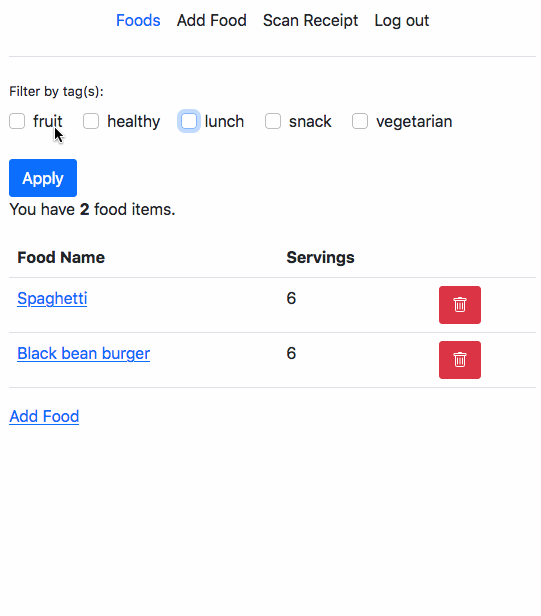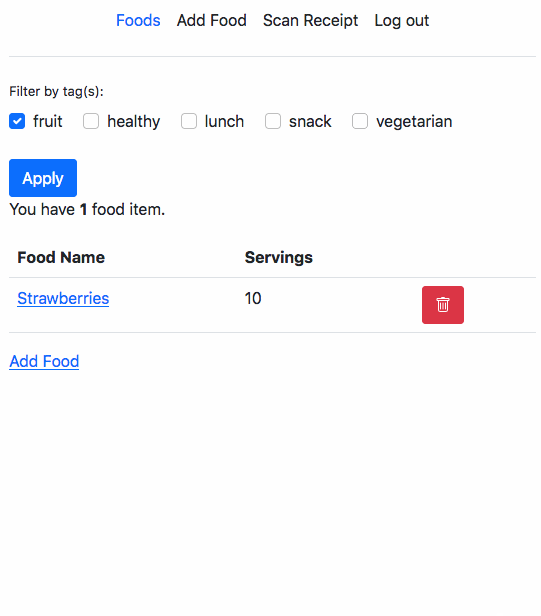
This is a part of a series of posts to document my learnings after watching Udi Dahan’s Advanced Distributed Systems Design course.
In this post, we will conclude our request/response analysis. We know that request/response may be unreliable, slow and not scalable.
However, it is not possible to completely avoid using request/response and still build a useful software system. Is there an alternative?
There is good news and bad news. The good news is that we can create reliable, scalable and performant software systems by strictly adhering to the proven principles that have been around for a long time such as loose coupling (more on this later) and encapsulation.
The bad news is that it is challenging to adhere to the principles in the face of marketing from tech vendors and cargo cult programming (Netflix, Uber are building microservices so should we… not so fast).
All you need to know about software:
Tightly coupled designs donot work.
Highly cohesive, encapsulated software loosely coupled from other
highly cohesive, encapsulated software work.
-Udi Dahan (paraphrased)
It is sort of an anticlimactic reveal. You would be hard pressed to find any software developer who have not heard these terms.
In traditional Object Oriented Design nouns become entities, relationships between the entities lead to entity-relationship diagrams (Customer, Order, CustomerOrder etc.) and that usually leads to architectures requiring quite a bit of request/response to do anything useful.
One of the issues with this approach is that we end up putting attributes that do not need to change together in the same place. In a typical Customer among other attributes object, we may see:
- Name
- Date of Birth
- Address
If a customer’s name does not change when they move, name and address donot need to be stored together.
This understanding leads us to one of the most important aspects of the distributed systems design: Finding your service boundaries.
In a nutshell,
- Design and understand user workflows
- Determine the pieces of data needed to enable the workflows
- Organize pieces of data into randomly named piles
- Identify messages/events needed for coordination between the piles
- Name the piles (like CustomerLoyaltyService, ShippingService etc. )
When teams follow this exercise they realize that the traditional singular “Customer” entity does not exist anymore. First name and last name is in this pile(service to be named later), shipping address is in that pile and loyalty status info is in that pile over there. Effectively, we have exploded the customer entity and distributed its attributes to many piles(prospective services). Ideally, these piles have an ID, customer attributes they are responsible for and nothing else so each can totally perform their respective business capability independently. That is what makes them a service.
Service is the technical authority for a given business capability.
-Udi Dahan
Note that I am oversimplifying the process here for the purposes of brevity. The process of identifying how the domain breaks down is reportedly a long, difficult and thankless process. Adam Ralph does a great job explaining the nuances in the webinar linked above. In reality, armed with the principles such as minimal request/response and no data sharing between services (no publishing events like CustomerAddressUpdated) it is a process of trial and error.
These aspects of the service boundary discovery process make it challenging to provide a nice explanation with examples in a blog post. Even the most experienced software architects describe it similar to bumping around in the dark and trying to get a sense of what the shape of the world around you -maybe for days- until discovering some insight.
It’s no surprise then why this approach is not popular among agile teams biased towards action who prefer working software over documentation, work in sprints and timebox their “spikes”.